 Help Center
Help CenterExcelでのk-meansクラスタリング・チュートリアル
このチュートリアルは、XLSTATソフトウェアを用いてExcel内でk-meansクラスタリング をセットアップして解釈することを支援します。 これがあなたの必要なクラスタリング・ツールであるか不確かな場合は、こちらのガイド を参照してください.
k-meansクラスタリングのデータセット
データは米国国勢調査局のデータで、2000年から2001年の51州での人口の変化を記述しています.初期のデータセットは、住人1000人あたりの割合に変換されており、2001年のデータが分析の対象になっています.
このチュートリアルの目的
我々の目的は、利用可能なデモグラフィック(人口動態)データに基づいて、州の均質なクラスタを作成することです.このデータセットは、主成分分析(PCA)および凝集型階層クラスタリング(AHC)のチュートリアルでも使用されています.
注意: 同じデータで下記に説明するのと同じ分析を実行しようとする場合、k-meansはランダムに選択されたクラスタから開始するので、乱数のシードをここで使用している値(4414218)と同じに固定しない限り、下記の結果とは異なる結果を得る可能性が高いことに注意してください.シードを固定するには、XLSTATオプションの'高度な機能'タブに行って、シードを固定オプションをチェックを入れてください。
XLSTATでのk-meansクラスタリングのセットアップ
XLSTATを起動すると、 下図の示すようにデータ解析 / k-meansクラスタリングを選択してください:
ボタンをクリックすると、k-meansクラスタリンス・ダイアログ・ボックスが開きます。Excel シートでデータを選択してください。
注意: XLSTATでは複数の選択方法があります - 詳細な情報はデータ選択 に関するチュートライルを確認してください。
この事例では、データが最初の行から開始しており、列選択モードを使用するのが、より素早くより簡単です。 これはなぜ列に対応する文字が選択ボックスに表示されるかを説明します。
一般タブで、クラスタリングを可能にする、以下の量的変数を選択します: - NET DOMESTIC MIG.
- FEDERAL/CIVILIAN MOVE FROM ABROAD
- NET INT. MIGRATION
- PERIOD BIRTHS
- PERIOD DEATHS
- < 65 POP. EST.
TOTAL POPULATION 変数は選択しませんでした。我々は主に人口動態のダイナミクスに興味があるからです。最後の列(> 65 POP. EST.) は、前の列と完全に相関しているので選択しませんでした。
各変数の名前が表の上部にあるので、変数ラベルのチェックボックスをチェックする必要があります。
グループの数を4個作成するように設定します。
選択された基準は Determinant(W) で、これは変数の尺度効果を除去することができます。非類似度指標としてユークリッド距離を選びます。これは、k-meansクラスタリングを使用する上で、最も伝統的な距離です。
オブザベーション・ラベル(STATE)があるので、最後にオブザベーション・ラベルが選択されました。
 オプションタブでは、結果の品質と安定性を増すために、繰り返しの数を10に増やしました。
オプションタブでは、結果の品質と安定性を増すために、繰り返しの数を10に増やしました。
 最後に、出力タブで、1個または複数の出力表を表示するように選ぶことができます。
最後に、出力タブで、1個または複数の出力表を表示するように選ぶことができます。
 ## k-meansクラスタリングの解釈
## k-meansクラスタリングの解釈
選択された変数の基本の記述統計および最適化要約の後、表示される最初の結果は、イナーシャ分解の表です。
繰り返しの中での最良解のイナーシャ分解表が表示されます。 (注意: 合計イナーシャ = クラス間イナーシャ+ クラス内イナーシャ)。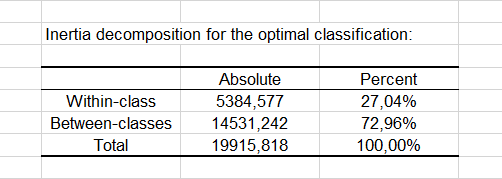 クラス・セントロイド、クラス・セントロイド間の距離、中心オブジェクト(ここでは、クラス・セントロイドの最も近い州)を含む一連の表の後、各クラスタに分類された州を示す表が表示される。
クラス・セントロイド、クラス・セントロイド間の距離、中心オブジェクト(ここでは、クラス・セントロイドの最も近い州)を含む一連の表の後、各クラスタに分類された州を示す表が表示される。
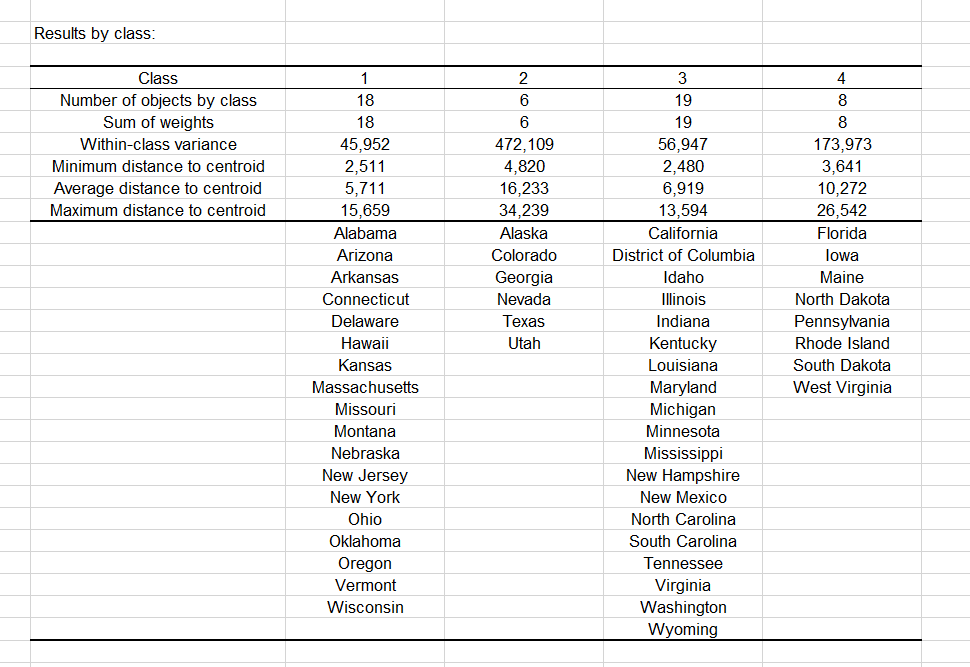 そして、各州のグループIDによる表が表示されます。下記にサンプルを示します。クラスタ IDは、さらなる分析(たとえば判別分析)のために初期の表と融合できます。
そして、各州のグループIDによる表が表示されます。下記にサンプルを示します。クラスタ IDは、さらなる分析(たとえば判別分析)のために初期の表と融合できます。
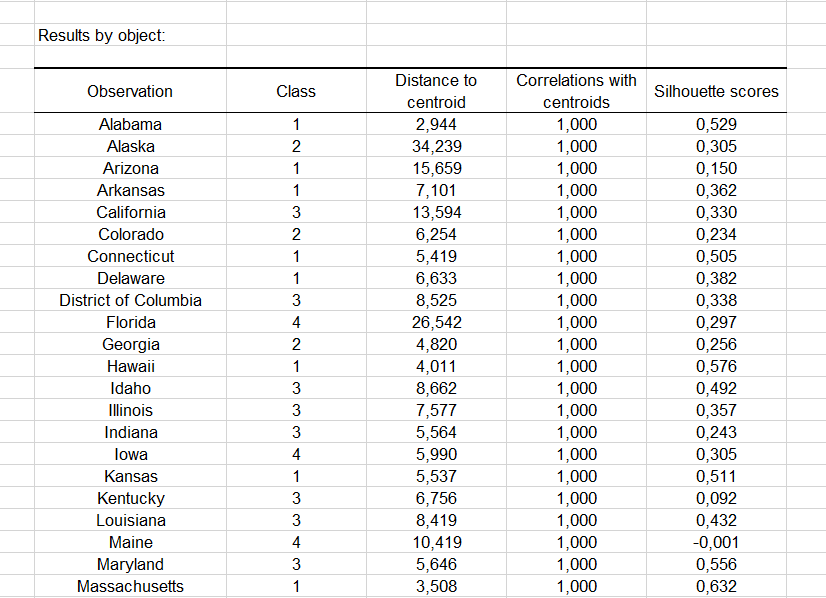
セントロイドとの相関 および シルエット・スコア オプションが有効にされると、同じ表に関連する列が表示されます:
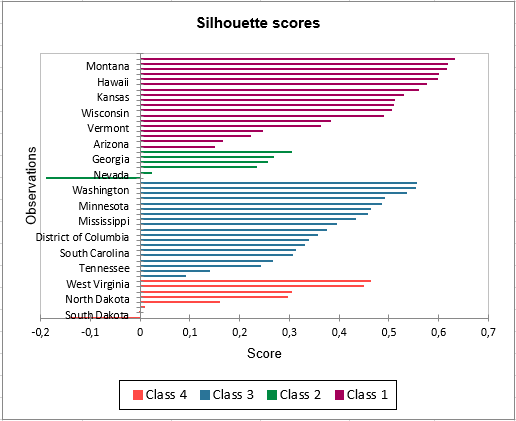
 シルエット・スコアを表すグラフは、クラスタリングの良好さを視覚的に調査できます。スコアが1に近いほど、オブザベーションがそのクラスによく当てはまります。反対に、スコアが-1に近いほど、そのオブザベーションは間違ったクラスに割り当てられていることになります。
シルエット・スコアを表すグラフは、クラスタリングの良好さを視覚的に調査できます。スコアが1に近いほど、オブザベーションがそのクラスによく当てはまります。反対に、スコアが-1に近いほど、そのオブザベーションは間違ったクラスに割り当てられていることになります。
 クラスごとの平均シルエット・スコアは、クラスを比較して、このスコアによると、どのクラスが最も均一であるかを教えてくれます。
クラスごとの平均シルエット・スコアは、クラスを比較して、このスコアによると、どのクラスが最も均一であるかを教えてくれます。
クラス 1 は、最も高いシルエット・スコアを持ちます。一方、クラス 2 は0に近いスコアで、それはこのデータでは、4が最良のクラス数ではないことを意味します。 凝集型階層クラスタリング(AHC) のチュートリアルで、 Statesが3つのグループによりよくクラスタされることがわかります。
Was this article useful?
- Yes
- No