 Help Center
Help CenterExcelでのロジスティック回帰チュートリアル
このチュートリアルは、XLSTATソフトウェアを用いてロジスティック回帰 をセットアップして解釈することを支援します。 これがお探しのモデリング機能であるかどうか不確かな場合は、こちらのガイドを参照してください。
ロジスティック回帰の原理
ロジスティック回帰、およびProbit分析などの関連の手法は、バイナリの応答変数、すなわち、たとえば 0/1 または Yes/No の2値のみをとり得る変数で、1個または複数の変数の効果を理解または予測したいときに役立ちます。
ロジスティック回帰は、医療での薬品の投与効果、農業での化学成分の投与効果、郵送に回答する顧客の傾向を評価するため、銀行での顧客の返済不履行リスクを定量化するためのモデル作成にとても役立ちます。
XLSTATにより、生データ(0または1で回答)で直接、または集計データ(回答が成功の合計-たとえば1-で、この場合、繰り返し数も必要)でロジスティック回帰を実行することが可能です。
ロジスティック回帰は、量的変数や質的変数の集合を与えて、あるイベントの発生確率をモデルします。
バイナリ・ロジット・モデルを実行するデータセット
以下で我々が考える事例は、顧客がオンライン情報サービスのサブスクリプションを更新する確率を予測しようするマーケティング・シナリオです。
データは、60人の読者の標本で、年齢カテゴリ、過去10週間の週あたりページ・ビューの平均数、先週のページ・ビューの数です。これらの読者は、サブスクリプションが2週間以内に期限切れになるので、更新を問われました。
目的は、なぜ一部の人々は更新して、なぜそれ以外の人々は更新しないのかを理解することです。
ロジスティック回帰に関するこのチュートリアルの目的
目的は、バイナリ・ロジスティック回帰を用いて調査から得られた結果を理解して、サブスクリプションを更新しないであろう人々を識別するために、全体集合にモデルを適用することです。
この情報により、マーケッターは、提案への彼らの興味を刺激するために、プロモーションまたは追加のサービスを提供することができます。
バイナリ・ロジット・モデルのセットアップ
バイナリ・ロジット・モデル・ダイアログ・ボックスを有効にするには、XLSTATを起動して、XLSTAT / データ・モデリング / ロジスティック回帰を選択します。

ボタンをクリックすると、ダイアログ・ボックスが現れます。Excel シートでデータを選択します。
応答データは、バイナリまたは量的変数が入っている列です(そしてバイナリの合計から生じます - この事例では次に"Weights" 列が選択されなければなりません)。
我々の事例では、3つの説明変数があります、1つは質的変数 - the age class - で、2つは量的変数で、ページ・ビューのカウントです。
我々は変数のラベルを選択したので、変数ラベル・オプションを選択しなければなりません。
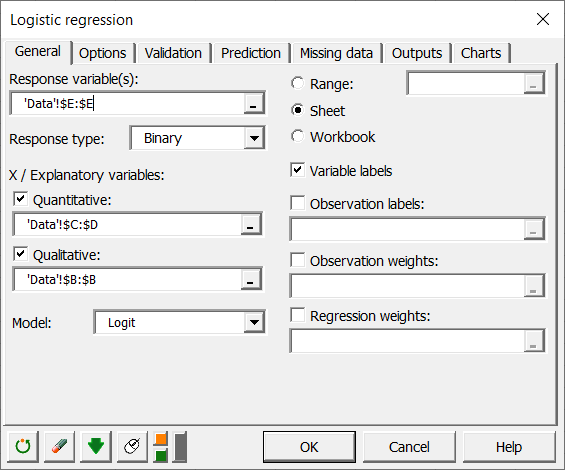
OK ボタンをクリックすると、計算が実行され、結果が表示されます。
バイナリ・ロジット・モデルの結果の解釈
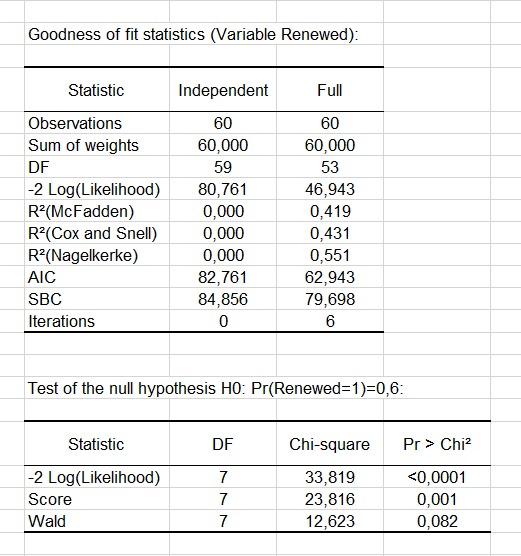
適合度統計表は、モデルの品質(または適合度)の複数の指標を提供する。これらの結果は、線形回帰やANOVA表の R² に相当します。最も重要な値は、**対数比(L.R.)**に関連する Chi² (カイ2乗)です。これは線形回帰のFisherのF検定に相当します: 我々は変数が応答変数の変動を説明するのに有意な情報量を提供するかどうかを評価しようとします。我々の事例では、この確率が 0.0001より低いので、変数が有意な情報量をもたらすと結論できます。
 つぎに、Type II 分析表 がモデルに関する最初の詳細を提供します。これは、応答変数の説明への変数の寄与度を評価するのに役立ちます。
つぎに、Type II 分析表 がモデルに関する最初の詳細を提供します。これは、応答変数の説明への変数の寄与度を評価するのに役立ちます。
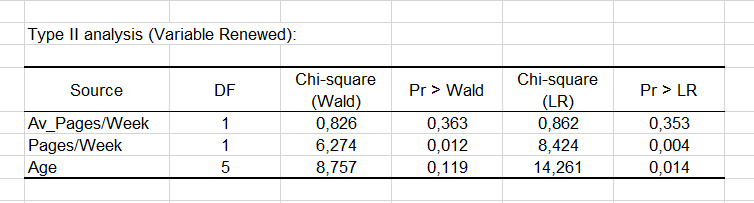 カイ2乗検定に関連する確率から、更新に最も影響する変数は、前の週のページ・ビューの数です (p = 0.012)。
カイ2乗検定に関連する確率から、更新に最も影響する変数は、前の週のページ・ビューの数です (p = 0.012)。
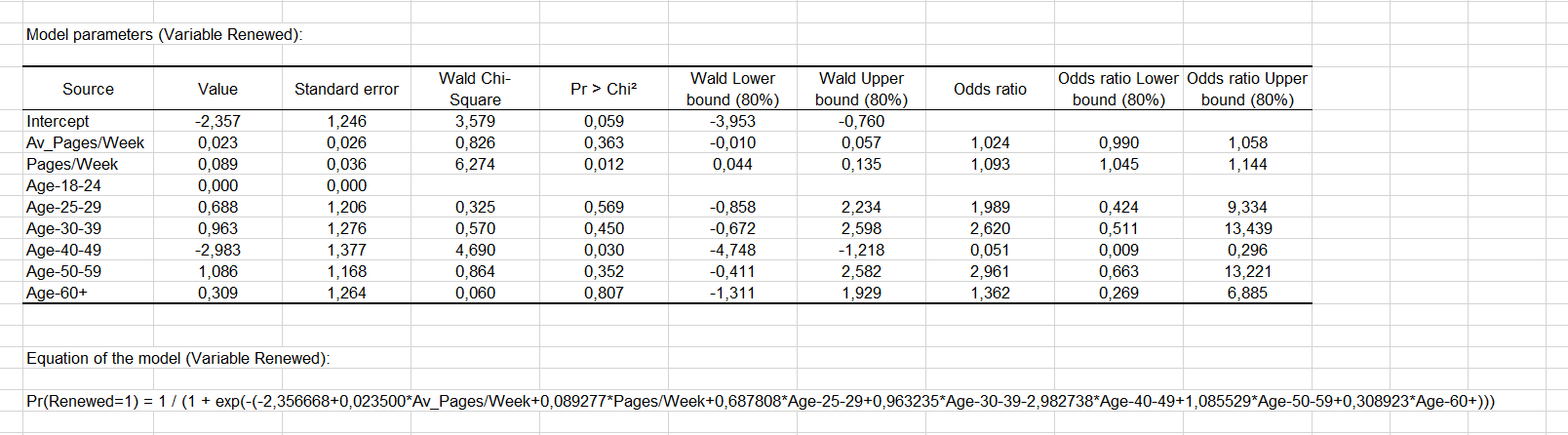
Age 変数は質的変数(グループに分割している)なので、我々は各モダリティが更新の決定に影響するかどうかを判断できます。“40-49” 歳のグループは、有意に負の影響 (-2.983)を持つようです。マーケティングおよび編集マネージャーは、なぜかを理解するために、さらにこれを調査できます。その他の年齢グループは、有意な効果を持ちません。
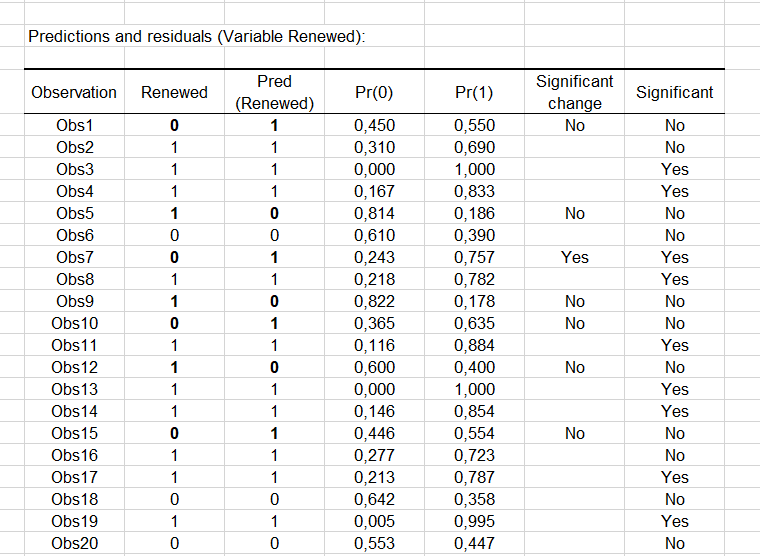
次に、予測値と残差の表を見ることができます。We can see that for the 7番目のオブザベーションについては、彼はサブスクリプションの更新に興味がないと主張していますが、モデルはサブスクリプションの更新を予測しています。実際、更新する確率は 0.757と推定されており、一方、更新しない確率は 0.243と推定されています。
列有意な変化は、予測モダリティと観察モダリティの間の値での変化を示します。2番目の列有意は、予測モダリティの確率がその他のモダリティの確率より有意に異なるかどうかを示します。 7番目のオブザベーションの場合、その変化は有意で、更新する確率 (0.757) が更新しない確率 (0.243)よりも高いことがわかります。
これらの2列は、ダイアログ・ボックスの"出力"タブで有意度分析オプションがチェックされた場合に現れます。
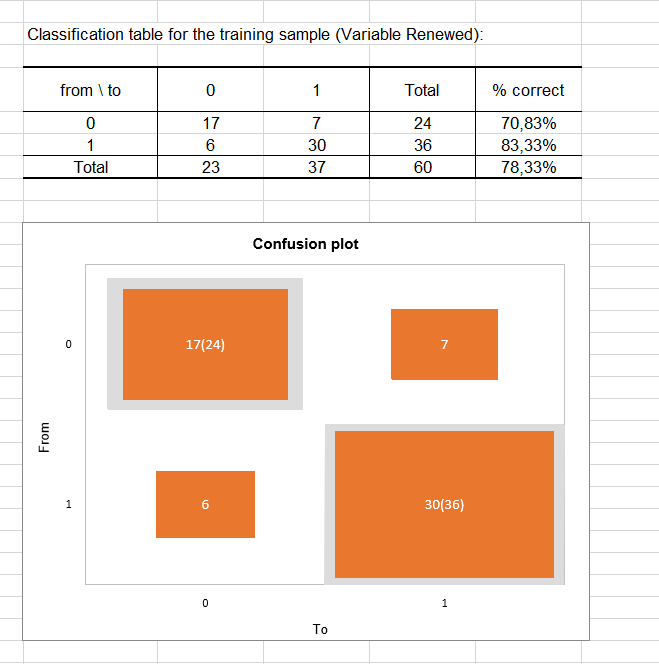
そして、トレーニング標本での分類表 (混同行列ともいう)がレポートに表示されます。この表は、各モダリティで正しく分類された(真陽性および視認性)オブザベーションのパーセンテージを示します。たとえば、 モダリティ0 (no renewal) のオブザベーションは70.83%正しく分類され、一方、モダリティ1 (renewal) のオブザベーションは83.33%正しく分類されたことがわかります。
混同プロットは、この表を合成的に可視化できます。 対角線の灰色の四角形は、各モダリティで観察された数を表します。オレンジの四角形は、各モダリティでの予測された数を表します。したがって、2つのモダリティで四角形の面がほとんど完全に重なっているのがわかります( モダリティ0で観察された24個のオブザベーションのうち17個の正しく予測されたオブザベーション、およびモダリティ1で観察された36個のオブザベーションのうち30個の正しく予測されたオブザベーション)。
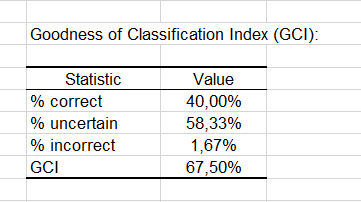
結局、最後の2つの表は不確実性を考慮しています。モダリティ0で行われたほとんどの予測は不確実 (95.83%)とみなされますが 、モダリティ1に関しては、不確実と推定されたパーセンテージが33.33%で、不確実性がはるかに少ないです。

GCI表は、オブザベーションの40%が正しく分類され(真陽性)、58.33%が不確実な分類で、1.67%だけが間違って分類された(偽陽性よび偽陰性)ことを示します。 GCI (Goodness of Classification Index) は **67.50%**で、それは、この分類モデルの予測品質が良好であることを意味します。
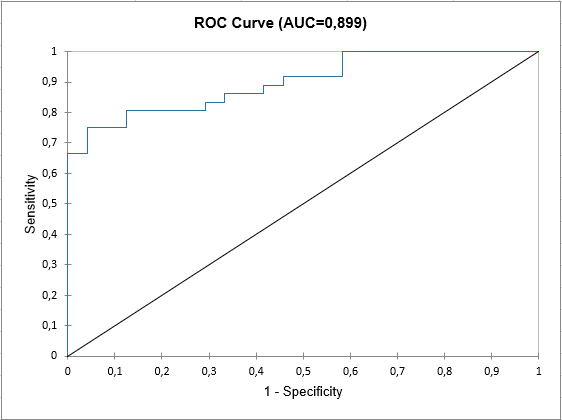
XLSTATの出力シートの最後に、ROC曲線が表示されます。 これは、モデルの性能を可視化し、他のモデルのそれと比較するために使用されます。
曲線の下側の領域(AUC)は、ROC曲線で計算される合成指標です。 AUCは、 正のイベントが負のイベントよりもモデルによって与えらた高い確率を持つような確率に対応します。理想モデルでは AUC=1 で、ランダム・モデルでは AUC = 0.5です。 AUC値が0.7より大きければ、通常、モデルが良好であるとみなされます。正しく判別するモデルは、0.87から0.9の間のAUCを持たなければなりません。0.9より大きいAUCを持つモデルは優秀です。
Was this article useful?
- Yes
- No