 Help Center
Help CenterExcelでのピアソン相関係数チュートリアル
ãã®ãã¥ã¼ããªã¢ã«ã¯ãXLSTATãç¨ãã¦Excelã§ãã¢ã½ã³(Pearson)ç¸é¢ä¿æ°Â ãè¨ç®ãã¦è§£éãããã¨ãæ¯æ´ãã¾ãããããæ¢ãã¦ããçµ±è¨æ©è½ããããã©ããããããªãå ´åã¯ããã¡ãã®ã¬ã¤ãããã§ãã¯ãã¦ã¿ã¦ãã ããã
ãã¢ã½ã³ç¸é¢ä¿æ°ãè¨ç®ãããã¼ã¿ã»ãã
ãã¼ã¿ã¨çµæã®Excelã·ã¼ãã¯ã以ä¸ã®ãªã³ã¯ãã¯ããã¯ãã¦ãã¦ã³ãã¼ãã§ãã¾ãï¼ ãã¼ã¿ããã¦ã³ãã¼ã
ãã®ãã¼ã¿ã¯ããªã³ã©ã¤ã³ã»ã·ã§ããã®é¡§å®¢ã®æ¨æ¬ã表ãã¾ããè¡ã顧客ã§åã¯å½¼ããè²»ãããéé¡ã¨ãã®ä»ã®ç¹æ§ï¼ãã¨ãã°ãé´ã®ãµã¤ãºãä½é...ï¼ã§ãã
ãã®ãã¥ã¼ããªã¢ã«ã®ç®ç
ããã§ã®ã´ã¼ã«ã¯ããªã³ã©ã¤ã³ã»ã¹ãã¢ã§è²»ãããéé¡ã¨ãã¾ãã¾ãªå±æ§ã¨ã®éã®ç¸é¢ãè¨ç®ãããã¨ã§ããç¸é¢ä¿æ°ã¯ã2ã¤ã®éçå¤æ°ã®éã®æ£ã¾ãã¯è² ã®é¢ä¿æ§ã®å¼·ãã表ãã¾ããæã ã®ãã¼ã¿ã¯ãé£ç¶å¤æ°ã§æ§æããã¦ããã®ã§ãæã ã¯ãã¢ã½ã³ç¸é¢ä¿æ°ã使ç¨ãã¾ããæã ã¯ã¾ããç¸é¢ã®ææ度ã®æ¤å®ãè¡ãã¾ãã
ããã¦ãæã ã¯2種é¡ã®ã°ã©ããçæãã¾ãï¼
- ç¸é¢ãè¦è¦çã«æ¢ç´¢ããããã®**ç¸é¢ããã**ãããã³
- å¤æ°ã®ãã¹ã¦ã®å¯è½ãªå¯¾ã®éã®é¢ä¿æ§ãå¯è¦åããããã®æ£å¸å³ã®ãããªãã¯ã¹
 XLSTATã§ã®ãã¢ã½ã³ç¸é¢ä¿æ°ã®è¨ç®ã®ã»ããã¢ãã
- XLSTATãéãã¨ãä¸å³ã®ããã« **ç¸é¢/å±æ§ç¸é¢ã®æ¤å® / ç¸é¢ä¿æ°ã®æ¤å®** ã³ãã³ããé¸æãã¦ãã ããã
  2. **ç¸é¢ä¿æ°ã®æ¤å®** ãã¤ã¢ãã°ãç¾ãã¾ãã
 2. **ç¸é¢ä¿æ°ã®æ¤å®** ãã¤ã¢ãã°ãç¾ãã¾ãã
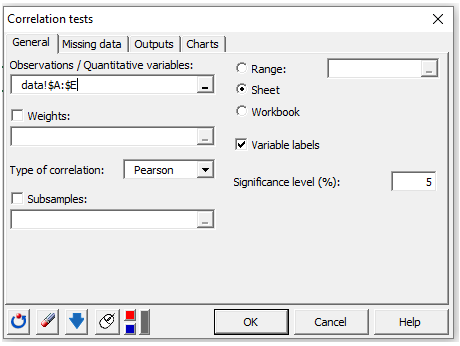
-
ä¸è¬ã¿ãã®ãªãã¶ãã¼ã·ã§ã³/éçå¤æ°Â ãã£ã¼ã«ãã§åA-Eãé¸æãã¾ããããã¦ããããããã¦ã³ã»ãªã¹ããã Pearson ç¸é¢ä¿æ°Â ãé¸ã³ã¾ããæåã®è¡ããããã¼ãªã®ã§ã**å¤æ°ã©ãã«** ãªãã·ã§ã³ããã§ãã¯ããã¾ã¾ã«ãã¦ããã¾ãã
-
åºåã¿ãã§ã以ä¸ã®ãªãã·ã§ã³ãæå¹ã«ãã¾ãã
ç¸é¢ä¿æ°ã0ã«çããã¨ãã帰ç¡ä»®èª¬ãæ¤å®ããããã«ãåä¿æ°ã«ã¤ãã¦på¤ãè¨ç®ããã¾ãã
決å®ä¿æ°ã¯ç¸é¢ä¿æ°ã®2ä¹ã§ãã決å®ä¿æ°ã¯ãç¸é¢ãè² ã§ããæ£ã§ãããç¸é¢ã®å¼·ããå®éåãã¾ãã**å¤æ°ããã£ã«ã¿**ãªãã·ã§ã³ãç¨ãã¦ãæã ã¯ä»ã®å¤æ°ã¨ã®R2ã®åè¨ãæãé«ã4ã¤ã®å¤æ°ã®ã¿ã表示ããããã«é¸æãã¾ãã
æå¾ã«**BAE(Bound Energy Algorithm)**ã ç¨ãã¦ãå¤æ°ã並ã¹æ¿ããã¾ãããã®ææ³ã¯ãè¡ã§ã®é¡ä¼¼ããå¤ãæã¤åããäºãã«è¿ã¥ãããã«æ£æ¹è¡åã®è¡ã¨åã«ä¸¦ã¹æ¿ããé©ç¨ãã¾ãã
- **ãã£ã¼ã**ã¿ãã§ã以ä¸ã®ãªãã·ã§ã³ãæå¹ã«ãã¾ãã
**ç»å**ã¿ãã§ã¯ãç¸é¢è¡åãç»åã§è¡¨ç¤ºããããã«é¸ã¹ã¾ãããã®ãªãã·ã§ã³ã¯ãç¸é¢è¡åãããããã®å¤æ°ãå«ãå ´åã«ãã©ã®å¤æ°ãåãæ§é ãæã¤ããç´ æ©ãè¦ãã®ã«å½¹ç«ã¡ã¾ãã
ãã¢ã½ã³ç¸é¢ä¿æ°ã®çµæã®è§£é
æåã®çµæã¯ããã¹ã¦ã®å¤æ°ã®è¨è¿°çµ±è¨ã§ããããã¦ãç¸é¢è¡åã表示ããã¾ãï¼
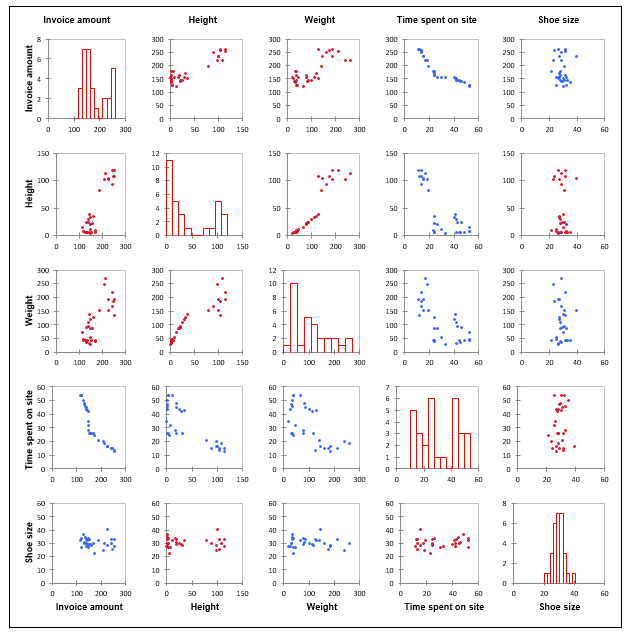
*Invoice amountï¼è«æ±é¡ï¼*ã¨å±æ§Â Height ã¨Â Weight ã®éã®ç¸é¢ã¯ãæ£ã§å¼·ãï¼1ã«è¿ãï¼ã§ããä¸æ¹ãTime spent ã¨Â Invoice amount ã®éã§è² ã®ç¸é¢ã観å¯ãããã¦ã§ããµã¤ãã§ããé·ãæéãããã顧客ã¯ãã¾ãå¤ããåºè²»ããªããã¨ã示åãã¾ãã
ãã¹ã¦ã®ä¿æ°ã0.05æææ°´æºã§ææã§ããã¨ãªã£ã¦ãã¾ãï¼å¤ªåã®å¤ï¼ãè¨ãæããã¨ã帰ç¡ä»®èª¬ï¼ä¿æ°=0ï¼ãçã§ããã«ããããããæ£å´ããããªã¹ã¯ã5%ãããå°ããã§ããããã¯ä¸è¨ã®på¤ã®è¡¨ã§ç¢ºèªã§ãã¾ã (på¤ < 0.0001)ã
shoe sizeã¯ç¸é¢è¡åã«è¡¨ç¤ºããã¦ããªããã¨ã«æ³¨æãã¦ãã ããããã®å¤æ°ã¯ãR2ã®åè¨ããã¹ã¦ã®å¤æ°ã®ãªãã§æãä½ãã®ã§é¤å¤ããã¾ããã
æ£å¸å³ã®ãã¤ã³ãã®è²ã¯ãæ£ï¼èµ¤ï¼ãè² ï¼éï¼ããæããã«ãã¾ããæ£å¸å³ã§è¦ããããã¿ã¼ã³ã¯ã2ã¤ã®å¤æ°ã®éã®é¢ä¿æ§ã®ã¿ã¤ãã¨åæã«ãã®å¼·ãã示ãã¾ãããã¨ãã°ã shoe size ã¯ãä»ã®ãã¹ã¦ã®å±æ§ã¨é¢ä¿æ§ãä¹ããï¼è¡åã®æå¾ã®åã¾ãã¯æå¾ã®è¡ï¼ãã¼ãã«è¿ãç¸é¢ãå«æãã¾ãã
次ã«ããã¹ããã¨: 主æååæã§éçå¤æ°ãæ¢ç´¢
主æååæ (PCA) ã¯ãå¤æ°éã®é¢ä¿æ§ãããã«æ¢ç´¢ãã顧客ãå¤æ°ã¨é¢ä¿ã¥ãããã顧客ã¨é¡§å®¢ãé¢ä¿ã¥ããããããã¨ã®ã§ããå¤å¤éésç³»ææ³ã§ããÂ
Was this article useful?
- Yes
- No