 Help Center
Help CenterExcelでのランダム・フォレスト・クラス分類チュートリアル
このチュートリアルは、XLSTAT統計ソフトウェアを用いてExcel内でランダム・フォレスト分類器をセットアップして訓練することを支援します。
ランダム・フォレスト分類器をセットアップするデータセット
データと結果のExcelシートは、下のボタンをクリックして ダウンロードできます: データをダウンロード このチュートリアルで使用するデータセットは、有名なデータサイエンス・プラットフォームであるKaggleでの"Titanic: Machine Learning from Disaster" という機械学習コンペから抽出されました。これは1912に沈没した遠洋定期船 Titanic に関するデータです。この惨事では、救命ボートの数が足りなかったために、2,224名の乗客のうちの1,500名が命を失いました。
このデータセットは、このアドレスでアクセスできます。それは 1309名の乗客の一覧とその特性を含みます。それらの特性は:
- survived: 生存l (0 = No; 1 = Yes)
- pclass: 乗客クラス (1 = 1st; 2 = 2nd; 3 = 3rd)
- name: 名前
- sex: 性別 (male; female)
- age: 年齢
- sibsp: 兄弟/配偶者の乗船数
- parch: 親/子供の乗船数
- fare: 運賃
- cabin: 客室
- embarked: 搭乗の港 (C = Cherbourg; Q = Queenstown; S = Southampton)
ここでの目的は、Titanic データセットでランダム・フォレスト分類器をセットアップして訓練することです。
XLSTATでのランダム・フォレスト分類器のセットアップ
XLSTATを開いて、下図のようにXLSTAT/ 機械学習 / ランダム・フォレスト分類器および回帰コマンドを選択してください。:
 ランダム・フォレスト・ダイアログボックスが現れます:
ランダム・フォレスト・ダイアログボックスが現れます:
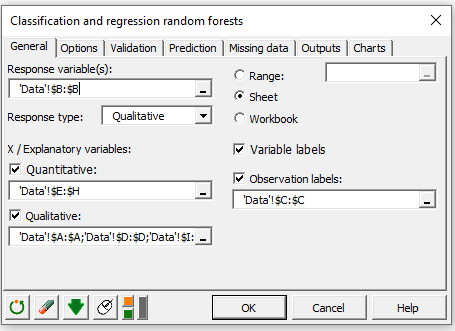 応答変数フィールドで変数 **ppclass (列B) を選択してください。ppclass は乗客のクラスを表しているので、応答タイプは質的データになります。
応答変数フィールドで変数 **ppclass (列B) を選択してください。ppclass は乗客のクラスを表しているので、応答タイプは質的データになります。
そして、 列 E-H を量的説明変数として、残りの列を質的説明変数として選びます。
変数名がデータセットの最初の行で提供されているので、変数ラベルを選択します。 最後に passengers’ names (列 C) をオブザベーション・ラベルとして選択します。
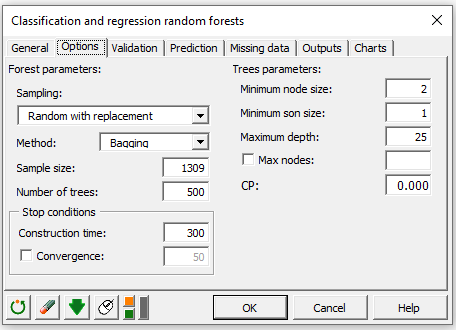
オプションタブでは、下図のように分類器パラメータを設定します:
 データセットに欠損値がありますので、欠損値タブでこれらのオブザベーションを除去するように選びます。
データセットに欠損値がありますので、欠損値タブでこれらのオブザベーションを除去するように選びます。
出力 タブでは、下図のオプションを選択します:
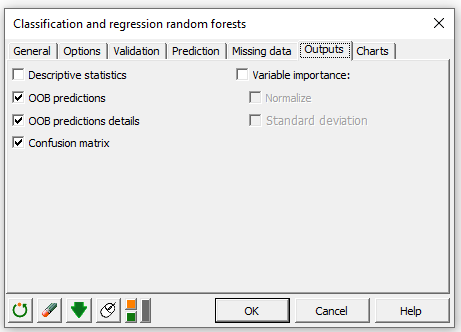 チャート タブでは、構築されるツリーの数に応じてOOB (Out Of Bag)誤差の推移を表示するように OOB誤差の推移オプションを有効にします。
OKをクリックすると計算が始まります。
チャート タブでは、構築されるツリーの数に応じてOOB (Out Of Bag)誤差の推移を表示するように OOB誤差の推移オプションを有効にします。
OKをクリックすると計算が始まります。
ランダム・フォレスト分類器の結果の解釈
最初のアウトプットは、ランダム・フォレストのOOB 誤差率 です。これは、トレーニング集合の各OOB標本に関係した平均分類誤差です。我々はすべての Out-Of-Bag オブザベーションからなる標本をOOB標本と呼びます。より詳細はヘルプで説明します。
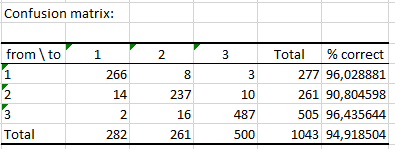
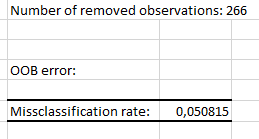 次の表は、混同行列を表示します。その行列は、我々の分類器がどれだけよく働くか(Out-Of-Bag データに基づく予測)を我々に示します。ここで、アルゴリズムは観察されたクラスの 94.92% を正しく予測しました。
次の表は、混同行列を表示します。その行列は、我々の分類器がどれだけよく働くか(Out-Of-Bag データに基づく予測)を我々に示します。ここで、アルゴリズムは観察されたクラスの 94.92% を正しく予測しました。
 2番目の表は、後者がOut-Of-Bagのとき、トレーニング集合の各オブザベーションについて、予測されたクラスを表示します。
2番目の表は、後者がOut-Of-Bagのとき、トレーニング集合の各オブザベーションについて、予測されたクラスを表示します。
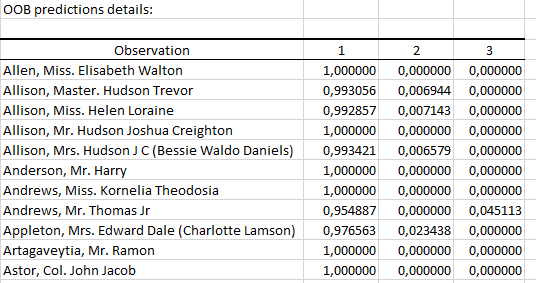
 次の表は、各オブザベーションについて、応答変数のさまざまなカテゴリに属する確率を (Out-Of-Bag データに基づいて)格納しています。
次の表は、各オブザベーションについて、応答変数のさまざまなカテゴリに属する確率を (Out-Of-Bag データに基づいて)格納しています。
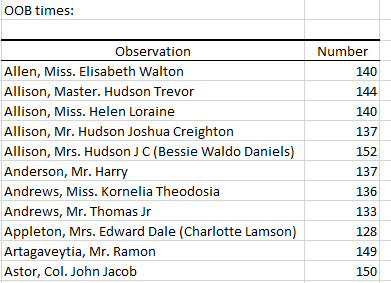
 オブザベーションが ‘out-of-bag’ である(そして、OOB 誤差推定の計算に使用される) 回数も表示されます:
オブザベーションが ‘out-of-bag’ である(そして、OOB 誤差推定の計算に使用される) 回数も表示されます:
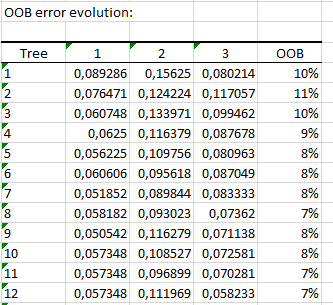
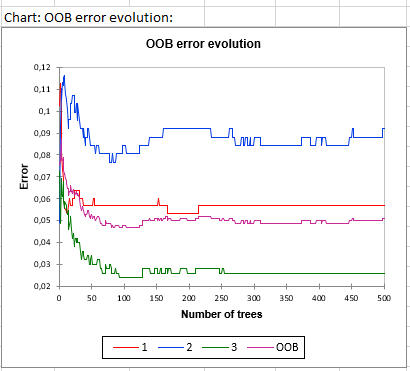
 最後の表は、ツリーの数による OOB 誤差率の推移を表します。 i番目の要素は、i番目までのすべてのツリーでのOOB 誤差です。
最後の表は、ツリーの数による OOB 誤差率の推移を表します。 i番目の要素は、i番目までのすべてのツリーでのOOB 誤差です。
 上記の表のグラフ表現が下図に与えられます:
上記の表のグラフ表現が下図に与えられます:
Was this article useful?
- Yes
- No