 Help Center
Help Centerk-meansクラスタリングの後にAHCを使用するビッグデータのクラスタリング
このチュートリアルは、XLSTATソフトウェアを用いてExcel内で k-means クラスタリング 、そのあとに凝集型階層クラスタリング (AHC) を用いて大規模データセットをセグメントすることを支援します。
クラスタするデータセット
データと結果のExcelシートは、下記のボタンをクリックしてダウンロードできます: データをダウンロード
データは米国の国税調査局のデータで、2000年から2001年の51州の人口変化を記述しています。初期データ集合は、分析の目的に合わせて、2001年のデータとの住民1000人あたりのレートに変換されました。我々の目的は、利用可能なデモグラフィック・データに基づいて、均質なクラスタを作成することです。このデータ集合は、あまり大きくありませんが、もっと大きなデータ集合を取り扱う場合の手順を説明する目的のためだけに用います。
注意: k-means 法は無作為に選択されたクラスタから開始するので、同じデータで、以下に説明するのと同じ分析を再実行しようとしても、以下の結果とは異なる結果が得られます。乱数のシードを固定するには、XLSTAT オプションの高度な設定タブに行って、"シードを固定" オプションをチェックします。
k-means クラスタリングのセットアップ
XLSTATを起動すると、 is activated, select the XLSTAT / データ解析 / k-means クラスタリング コマンドを選択するか、データ解析 ツールバー(下図)の対応するボタンをクリックしてください。
ボタンをクリックすると、k-meansクラスタリング・ダイアログ・ボックスが現れます。
Excelシート上のデータをマウスで選択してください。(注意: XLSTATではデータ選択の方法が複数あります。 - 詳細な情報は、データ選択に関するチュートリアルを確認してください。) この事例では、最初の行からデータが開始しているので、"列選択" モードを使用するのが早くて簡単です。これは、なぜ列に対応する文字が選択ボックス内に表示されるか (C から H)を説明します。
我々の興味は、おもにデモグラフィックのダイナミクスにありますので、変数Total populationは選択されませんでした。 最後の列は、前の列に完全に相関しているので選択されませんでした。オブザベーション・ラベルが利用可能なので、選択されました。
作成するグループの数を25に設定します。とても大規模なデータ集合の場合、より大きな数を使用できます。
選択された基準は、"行列式(W)" です。これは、変数の尺度効果を除去できます。
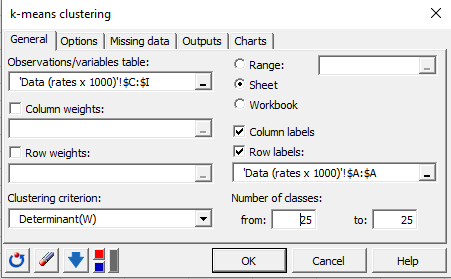
オプション・タブでは、結果の品質と安定性を増加させるために、繰り返しの数を 50 に増やしました。
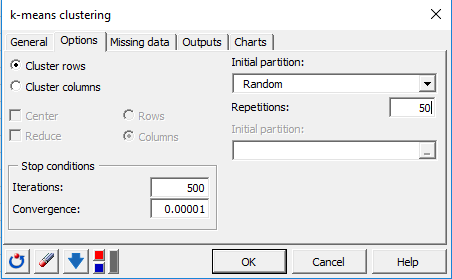
出力タブでは、AHCでよく使用するセントロイド(重心)、各クラス内の標本を出力するクラスごとの結果、, 属性変数による標本の表を出力するオブジェクトごとの結果のみを選択します。
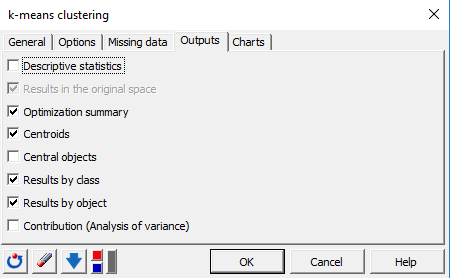
OK をクリックすると、k-means クラスタリングの結果が新しいシートに現れます。
k-means クラスタリングの結果での凝集型階層クラスタリング
我々は、Class centroids(クラス重心)の表で作業をします
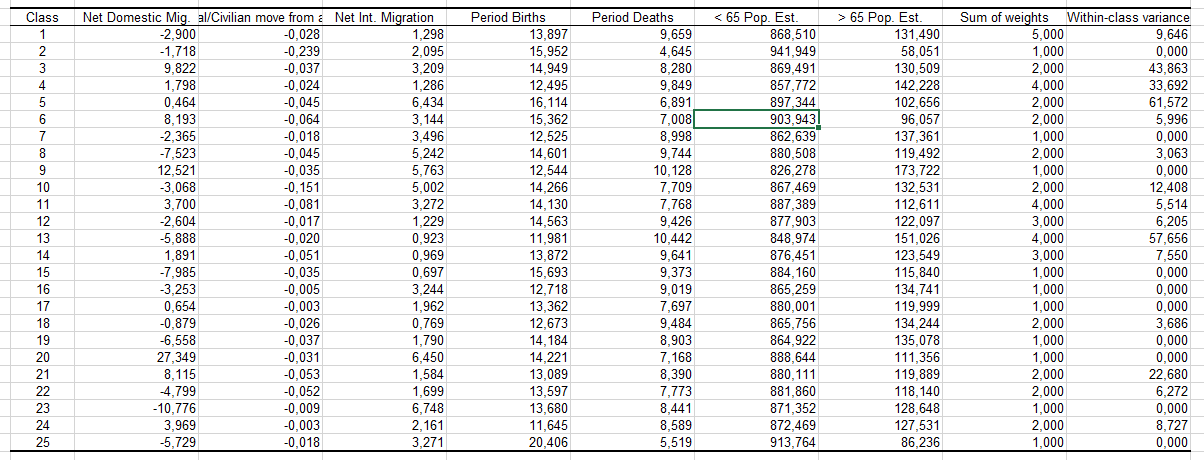
もう1つの重要な表は、どの州が一緒にクラスタさrているかの情報を含む表です。
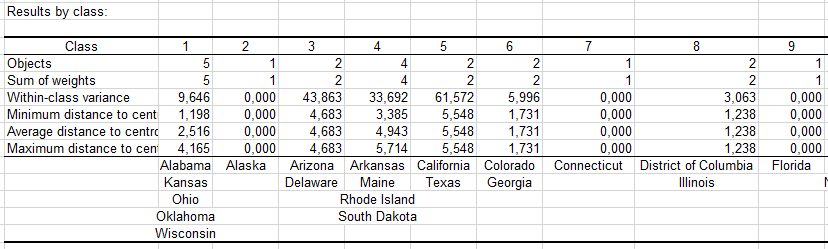
ここで、XLSTAT / データ解析 / 凝集型階層クラスタリングコマンドを選択するか、"データ解析"ツールバー(下図)の対応するボタンをクリックしてください。

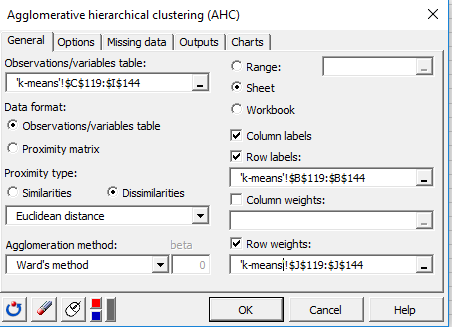
一般タブでは、クラスタするデータを選択する必要があります。Class centroidsの表で25個のクラスを説明するオリジナルの変数を選択します。
ここでは、近接タイプとして非類似度およびユークリッド距離、凝集法としてWard法を使用します。
選択内に変数の名前が含まれるので列ラベルをチェックし、クラスタ番号(1-25)の行ラベルを選択します。
行重みオプションを使用し、同じ表 Class centroidsの列Sum of weightsを選択します。
クラスが行にありますが、このタイプのクラスタリング(k-meansのあとのAHC)ではクラス内分散を含める必要があるので、オプションタブでは、行をクラスタのままです。前と同じ表 Class centroidsの列Within class varianceにこの情報があります。
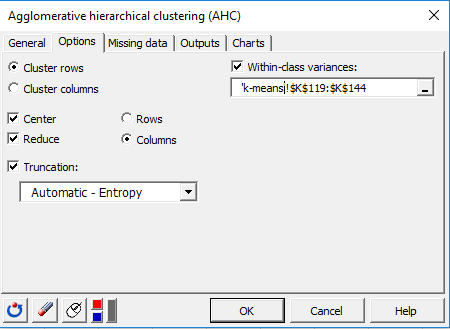
この分析では、すべての出力を選択できます。
最後にチャートタブで、すべてのチャートを選択します。ダイアグラムのタイプに特別な注意を払い、垂直オプションを選択してください。
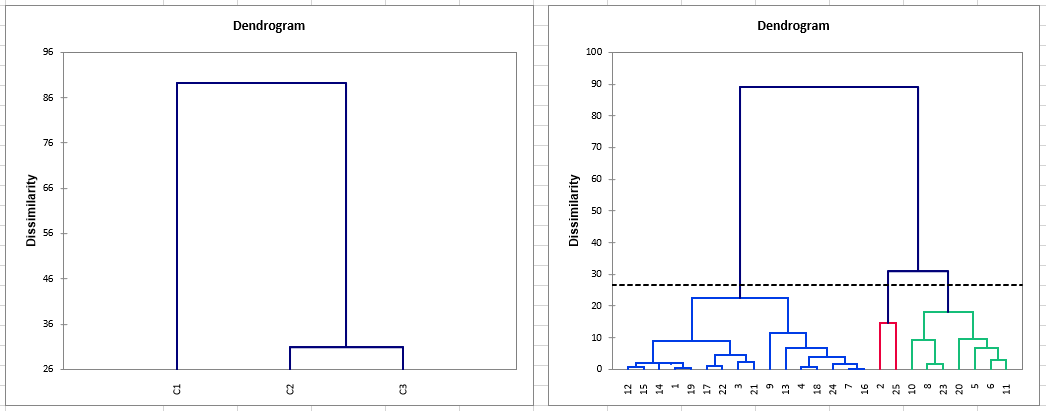
凝集型階層クラスタリングの結果
AHCの結果では、3つのクラスタの構成を示す2つのデンドログラムに注目してください。25個のクラスタが、どのように3つの最終クラスタに再クラスタリングされているかがわかります。
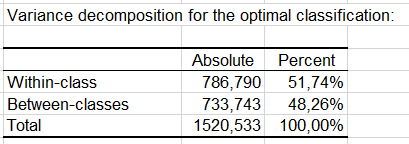
また、クラス内とクラス間での分散の分解を見ることができます。
最終の結果を得るために、AHCで得られた表を用いて、k-means クラスタリングで得られた表を再コードすることができます。XLSTAT / データ準備 / コーディングに行ってください。
再コードする変数として、k-meansクラスタリングで得られたクラス表から列Class を選択する必要があります。コーディング表としてAHCから表オブジェクトごとの結果(Result by object )を列の名前を含めて選択してください。そして、列ラベルオプションを選択します。.
最初の表に新しい列を追加するために、範囲オプションを選択して、表の隣のセルを選択してください。また、他に何も表示しないように、レポート見出しの表示オプションのチェックを外します。
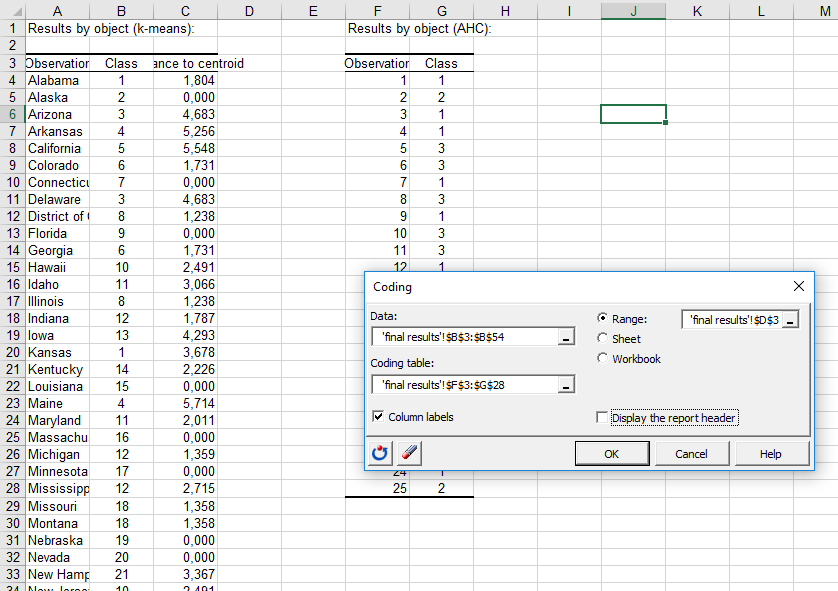
最終的に、すべての州に関するクラスタリングの結果を得ます。
Was this article useful?
- Yes
- No